Getting search results faster with Elasticsearch

At Furnify we cataloged thousands of products into the system. Using MySQL as our primary database it takes ages to get search results when users surf the search console.
This article is about providing a seamless search experience to the user using Elasticsearch with a Spring boot application backed with MySQL database.
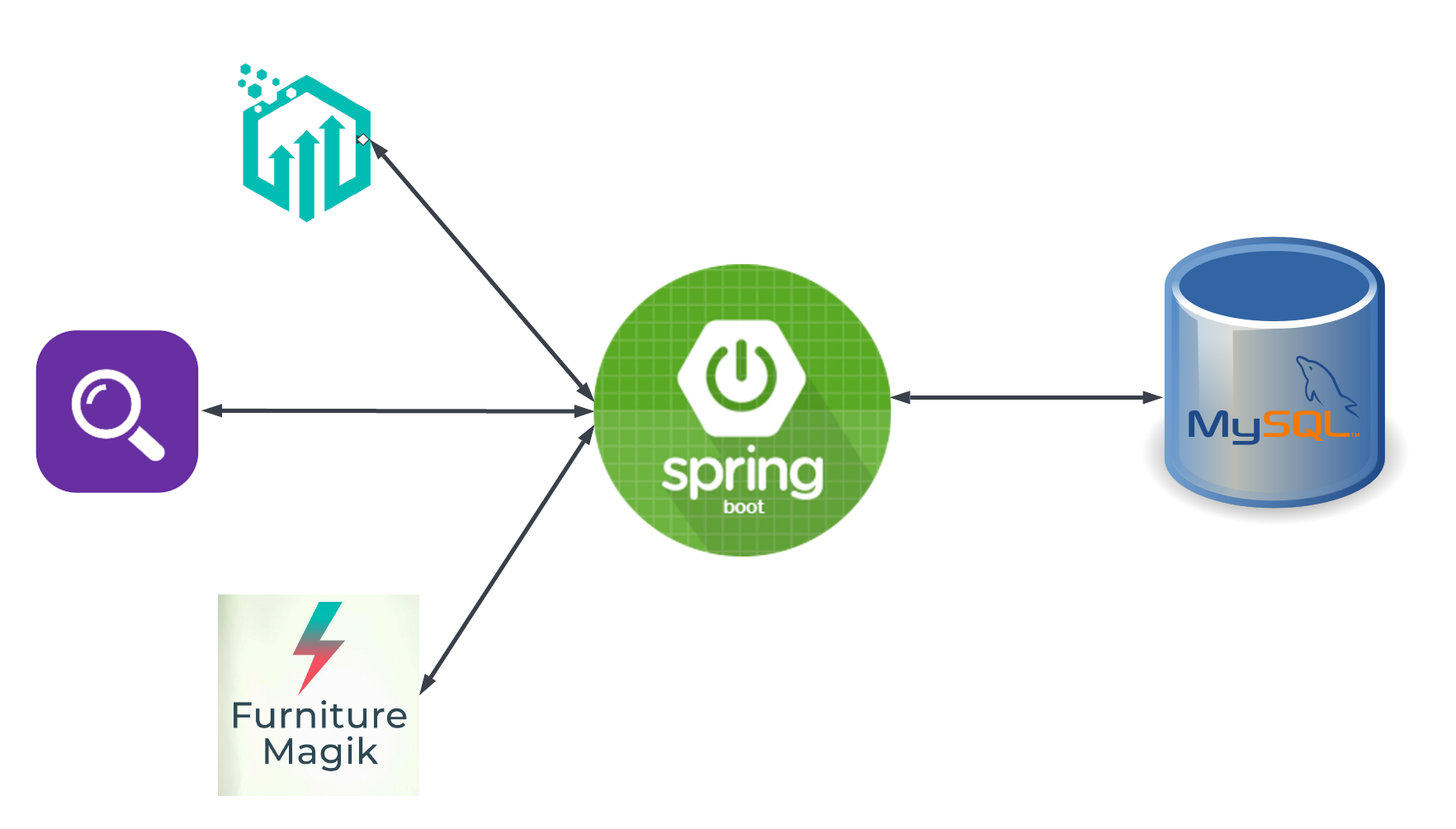
Application architecture
We have built an application that manages the whole inventory, sales, purchases, tickets, and CRM. We did that using spring boot for providing APIs and MySQL to store the data. We have multiple clients like retailers and customers who browse products and make orders via a mobile app or web app, and our team with a dashboard to manage all the data.
Data in MySQL
As a growing business, we should make sure that our data should be structured in the right way to view the proper analytic insights. Which can be used for forecasting our sales in the longer run. So that we are using a relational database as our primary data source.
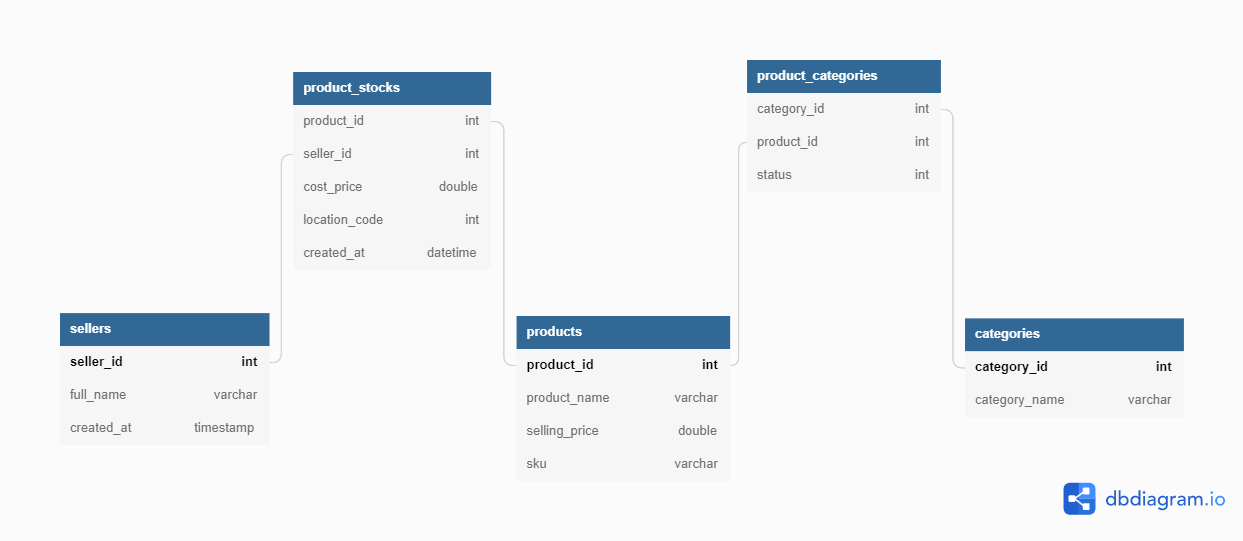 We have sellers who have their products in different locations/cities, and some of the products have many sellers. To handle this we designed our schema based on the Entity–attribute–value model. Now we can easily map not only between products, sellers, and their respective stock details but also with categories and attributes.
We have sellers who have their products in different locations/cities, and some of the products have many sellers. To handle this we designed our schema based on the Entity–attribute–value model. Now we can easily map not only between products, sellers, and their respective stock details but also with categories and attributes.
Problem statement
In our design system, we have lots of foreign key mappings. To get a single product detail we need to look up attributes, categories, stocks, and product schemas. Also, users may try to search by different parameters like category name or product color, or by price range. This makes it harder to get dynamic search results using a relational database.
How can Elasticsearch solve this?
Elasticsearch is a search engine based on the Lucene library. It provides a distributed, multitenant-capable full-text search engine with an HTTP web interface and schema-free JSON documents ~Wikipedia
In Elasticsearch, an index is really an inverted index, which is the technique that all search engines use. It is a data structure that holds a mapping between information (such as words or integers) and their positions in a document or collection of documents. It is simply a hashmap-like data structure that guides you from a word to a text. An inverted index does not store strings directly, but rather divides each document into individual search terms (i.e. each word) and then maps each search term to the documents in which those search words appear.
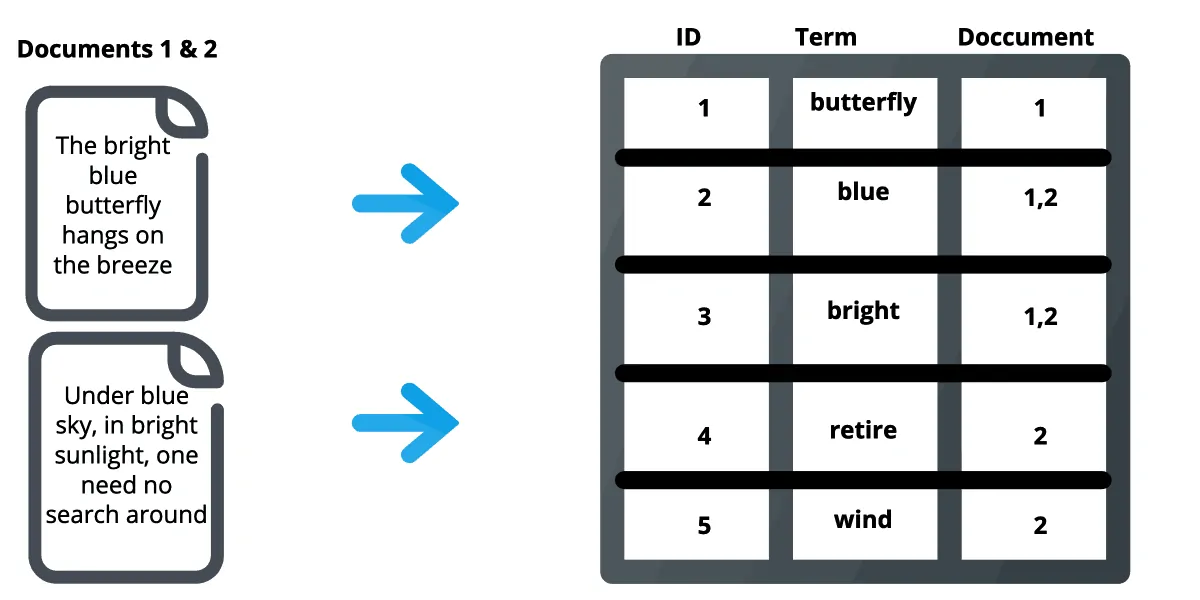
With Elasticsearch we can index all the product details with necessary details as JSON. This helps to retrieve the search results 90% faster than the existing one.
Integration
We don't encourage our client applications to directly access our Elasticsearch server. Instead, the search API calls will be processed by our spring boot server.
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.14.0</version>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-client</artifactId>
<version>7.14.0</version>
</dependency>
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>7.14.0</version>
</dependency>
Adding dependencies needed for Elasticsearch
We make sure that both MySQL and Elasticsearch are in sync by running scheduled jobs at regular intervals. Here we are indexing and retrieving data by Java client APIs of Elasticsearch.

Finally
As a consumer-first firm, we at Furnify are driven to deliver a high-quality, upgraded, and buttery smooth user experience in addition to an engaging user interface. Thus Elasticsearch helps us in achieving that via an enhanced search mechanism.
